데이터 분석 과정
데이터 분석 및 기획 ▶ 데이터 전처리 ▶ 탐색적 데이터 분석(EDA) ▶ 데이터 분석 모델링
▶ 평가 및 결론 도출 ▶ 분석 결과 활용
▶ 함수와 기능을 활용한 데이터 전처리
데이터 전처리 데이터 분석 목적과 방법에 맞게 데이터를 가공 또는 처리하는 과정
- "Garbage in, Garbage out" 데이터 분석 과정 중 60~80%의 시간과 비용이 드는 과정
데이터 분류
- IF 함수: 부등호로 가정 설정하여 만족하는 값 / 만족하지 않는 값으로 분류
= IF(logical_test, [value_if_true], [value_if_false] )
= IF(조건(가정), 조건 만족 시 표시 값, 조건 만족하지 않을 시 표시 값)
> IF 함수 중첩: IF함수를 N번 중첩 사용 시 데이터는 N+1개로 구분됨
데이터 추출
- VLOOKUP 함수: 원 데이터의 공통 기준열
= VLOOKUP(lookup_value, table_array, co_index_num, range_lookup)
= VLOOKUP(찾을 기준 데이터, 불러올 데이터 범위, 불러올 데이터 열 번호, 0 )
> (co_index_num) 열 번호 참조
> (co_index_num) MATCH 함수 대입
= MATCH(lookup_value, lookup_array, [match_type] )
= MATCH(찾고 싶은 값*, *이 포함된 단일 열/행 범위, 일치(0)/근사치(1,-1))
- INDEX & MATCH 함수
데이터 계산 ✓ 주로 합계나 개수 데이터 많이 쓰임
- COUNT 함수 함수 숫자 데이터의 개수
- COUNTA 함수 비어있지 않은 셀의 개수
- COUNTBLANK 함수 빈 셀의 개수
- COUNTIF 함수 특정범위 내 하나의 조건을 만족하는 셀의 개수
✓ 부등호 조건을 넣을 때는 쌍 따옴표 써야 함(IF 함수에서는 좌항이 비어있어 완전한 부등식이 아니기 때문에)
- COUNTIFS 함수 특정 범위 내 2개 이상의 조건을 동시에 만족하는 셀의 개수
- SUMIF 함수 SUMIF(조건 범위, 조건, 더할 값 범위)
- SUMIFS 함수 SUMIFS(더할 값 범위, 조건 범위 1, 조건 1, 조건 범위 2, 조건 2)
텍스트 데이터 처리
- FIND 함수 긴 텍스트 내 특정 단어/문장 시작 위치 숫자로 출력
띄어쓰기 포함, 대소문자 구분 - 구분하지 않아야 할 때는 SEARCH 함수 사용
=FIND(찾을 텍스트, 긴 텍스트, 찾기 시작할 위치)
- LEFT & RIGHT 함수 텍스트의 가장 왼쪽/오른쪽부터 원하는 문자열까지 추출
=LEFT/RIGHT(전체 텍스트, 불러올 문자열 수)
- MID 함수 텍스트의 중간 시작 위치부터 원하는 문자열까지 추출
기능을 활용한 데이터 전처리
- 텍스트 나누기: [데이터]탭 → [텍스트 나누기] → [구분 기호로 분리됨] → [기타] 체크 → “-” 입력 → [마침]
- 중복된 항목 제거하기
▶ 탐색적 데이터 분석(EDA)
본격적인 데이터 분석에 앞서 데이터 탐색 과정을 거치며 어떤 변수가 결론에 많은 영향을 미치는지와 변수의 분포에 따라 사용할 통계적 방법론을 판단한다. 이 때 실질적으로 하게 되는 작업은 다음과 같다.
- 유의미한 변수 탐색
- 변수 간 독립성 확보
- 효율성을 위한 차원 축소: 의미 없는 데이터 제거 - 분포에 따른 통계적 방법론 판단
- ex) 정규분포를 따르는지 판단: t-test 통해 결론 도출
탐색적 데이터 분석(EDA)는 1. 통계적 데이터 분석 2. 데이터 시각화 3. 상관 분석 4. 결측치, 이상치 탐지 등의 방법을 활용한다.
1. 통계적 데이터 분석
데이터 탐색을 하며 가장 먼저 적절한 통계 기법을 활용하여 수치를 뽑는데, 데이터로부터 올바른 정보를 얻기 위해 통계공부가 필요하다.
통계학은 크게 기술 통계학과 추론 통계학으로 분류된다.

기술 통계(Descriptive Statistics)
요약 통계량, 그래프 표 등을 이용해 데이터를 정리, 요약하여 데이터의 전반적인 특성을 파악하는 방법이다. 관측된 데이터의 특성을 파악하기에 좋은 수단이다. 엑셀의 기술통계법 요약통계량과 피벗테이블을 통해 기술통계량을 확인할 수 있다.


✓ 분포를 확인할 때 함께 확인해야 하는 수치
1. 중심경향성
- 최빈값: 범주형 자료에서 대표값으로 최빈값을 주로 사용
- 중앙값: 순서형 자료의 대표값으로 적합. 이상치에 크게 영향받지 않음.
- 산술 평균: 주로 연속형 자료에 사용. 이상치에 영향을 크게 받음
- 가중평균: 자료의 중요도에 따라 가중치를 부여한 평균
- 기하평균: 성장률, 평균성장률 등 이전 시점 비율들의 평균을 구할 때 유용
2. 퍼짐정도
- 분산: 편차 제곱의 평균. 보통 모분산보다는 표본분산 사용
- 표준편차: 분산을 제곱근한 값
- 범위: 최대값-최소값.계산과 해석이 쉽지만 관측값 분포에 대한 정보를 알 수 없고 이상치가 미치는 영향이 매우 큼
- IQR: 제3사분위수 - 제1사분위수. 주로 한 쪽으로 치우친 분포의 퍼짐 정도를 확인할 때 사용
3. 분포의 모양(비대칭성)
1) 왜도
- 분포가 정규분포에 비해 얼마나 비대칭적인지를 나타내는 지표.
- > 0 (좌편향성) / = 0 (좌우대칭) / < 0 (우편향성)
2) 첨도
- 평균을 중심으로 얼마나 모여있는지 나타내는 지표
- 양쪽 꼬리의 두터움 정도를 나타냄
- 편차가 큰 데이터가 많을 수록 커짐
- 이상치에 영향을 많이 받음
추론 통계
데이터가 모집단으로부터 나왔다는 가정하에 모집단으로부터 추출된 표본을 사용하여 모집단의 특성을 파악하는 방법으로, 통계량을 가지고 모수를 추정하는 것이라고 할 수 있다.
- 모집단 조사 대상이 되는 전체 집합
- 모수 모집단에 대해 요약된 수치(값에 대한 평균, 비율 등). 알고싶은 값
하지만 모집단 전부를 조사하기는 어렵기 때문에 표본을 뽑아 그에 대한 통계량을 조사한다.
- 표본 모집단을 대표하는 모집단의 일부. 모집단의 특성을 담을 수 있는 대표성이 중요함
- 통계량 표본에 대한 수치적 요약.
이를 가지고 모평균과 표본평균, 모분산과 표본분산을 구할 수 있다.
- 모평균 모집단의 평균
- 표본평균 모집단의 일부인 표본에 대한 평균
- 모분산 모집단의 분산
- 표본분산 모집단의 일부인 표본에 대한 평균
✓ 모분산과 표본분산을 구하는 식은 서로 다르다.
모분산과 표본분산을 구할 때 분산의 계산에서 필요한 표본평균과 표본 수에 대한 정보가 없기 때문이다. 엑셀에서는 모집단 전체의 자료가 있을 때는 끝에 .p가 붙은 함수를 쓰고, 표본 자료만 있을 경우엔 끝에 .s가 붙은 함수를 써 각 값을 구한다.
ex) 모분산(var.p), 표본분산(var.s), 모표준편차(stdev.p), 표본표준편차(stdev.s)
모집단을 추정하기 위해 표본 추출 시, 구해진 값이 모평균이라고 믿을 수 있는 정도를 신뢰도라고 하는데 보통 95%, 99% 정도의 구간을 신뢰구간으로 추정한다. 신뢰구간은 신뢰도와 표본의 수에 따라 달라지는데, 이 때 표본이 커질 수록 정규분포가 좁아지며 모평균에 가까워진다.

ㅣ가설 검정
가설 검정은 통계적 추론의 하나로서, 모집단 실제의 값이 얼마가 된다는 주장과 관련해 표본의 정보를 사용해서 가설의 합당성 여부를 판정하는 과정이다.
- 귀무 가설
기본적으로 참으로 추정되며 처음부터 버릴 것으로 예상하는 가설(차이가 없거나, 의미 있는 차이가 없는 경우) - 대립 가설 ✓ 귀무가설을 기각하는 반증의 과정을 거쳐 참이라고 받아들여질 수 있음
귀무 가설에 대립하는 명제로 보통 독립 변수와 종속 변수 사이에 어떤 특정한 관련이 있다는 결과가 도출된다.

이러한 가설 검정의 기준은 귀무 가설이 맞다는 전제 하에, 표본에서 실제로 관측된 통계치와 '같거나 더 극단적인' 통계치가 관측될 확률인 p-value(유의 확률)이다. p-value가 유의수준(전체의 5%)보다 작으면 귀무가설을 기각할 수 있다.

ㅣt-test
두 집단 혹은 한 집단의 전/후의 평균에 유의미한 차이가 있는지 검정하는 방법으로, 제약회사에서 신약 개발 시 약의 효과를 확인하기 위해 약 복용 여부가 다른 두 집단 혹은 한 집단의 약 복용 전/후의 차를 확인하는 식으 사용한다. 적합한 t-test 방법을 선택하기 위해서는 F 검정이 필요하다.

- F-검정
두 집단의 분산에 통계적으로 유의미한 차이가 있는지를 검정
- P-value > 0.05(유의수준) 두 집단의 분산에 유의미한 차이가 없다(F-검정의 귀무가설)
- P-value < 0.05(유의수준) 두 집단의 분산에 유의미한 차이가 있다(F-검정의 대립가설)

2. 데이터 시각화
데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달되는 과정이다. 차트를 통해 분포를 확인 하기 위해 데이터 탐색에도 활용되며 의사결정자가 데이터 간의 관계를 식별하고 숨겨진 패턴이나 추세를 감지할 수 있도록 데이터에 시각적 형태를 부여하는 역할을 하기도 한다.


3. 상관 분석
두 변수가 어떤 선형적 관계를 갖고 있는지를 분석하는 방법으로, 각 변수 간의 비례관계를 파악할 수 있다. 상관 분석을 통해 인과 관계가 있을 것으로 예상되는 변수들을 선별해 분석의 우선순위를 정할 수 있어 시간과 비용의 효율성이 증대된다.
- 상관관계
한쪽이 증가하면 다른 쪽도 증가하거나 반대로 감소되는 경향을 인정하는 두 양(量) 사이의 통계적 관계
→ 상관 계수를 통해 파악 - 상관 계수
- 상관 계수 r은 두 변수 사이의 상관성을 나타내며 일반적으로 피어슨(Pearson) 상관 계수를 사용
- 상관 계수가 1에 가까울 수록 양의 상관 관계(정비례), -1에 가까울수록 음의 상관 관계(반비례)
- 상관 계수표 분석 대상 변수들의 상관 관계를 한 눈에 보여주는 표

✓ 상관 분석에서 가장 유의해야 할 점
인과 관계를 가지고 있는 두 변수는 항상 강한 상관 관계를 가지고 있지만, 강한 상관 관계를 가지고 있다고 해서 두 변수가 반드시 인과 관계를 가지는 것은 아니다. 이 때는 상관 관계가 높은 변수들을 중심으로 실험을 통해 인과 관계를 경험적으로 입증해야 한다.
공분산과 상관계수
- 공분산
- 2개의 확률변수 사이의 선형 관계를 나타내는 값
- 공분산의 부호: - (음의 상관관계), 0 (상관관계 X), + (양의 상관관계)
- 표본공분산: 자료가 평균값으로부터 얼마나 떨어져 있는지를 나타낸 것
- 두 변수가 아무 관계없는 독립 변수일 때 공분산은 0이 되지만, 공분산이 0이라고 해서 두 변수가 반드시 독립변수인 것은 아님 - 상관계수
변수 간의 관계나 경향성을 비교할 때, 각각의 독립변수 별로 크기가 달라 이에 영향을 받는 공분산으로는 변수를 비교하기 어렵다. 상관관계를 비교하기 위해 표준화를 거치는데, 표준화된 값인 상관계수는 절대값이 0.5~0.7 이상일 경우 강한 상관 관계를, -0.2~0.2 정도일 경우 상관관계가 약하거나 없다고 해석한다.
4. 결측치, 이상치 탐지
관측되지 않거나 추세에서 벗어난 데이터 확인
결측치 데이터에 값이 없는 것
이상치 특정 지정된 그룹에 분류되지 못하는 값으로, 정상군의 상한과 하한의 범위를 벗어나 있거나 패턴에서 벗어난 수치
→ 일반적으로 -3σ(표준편차) 미만, +3σ 초과인 값을 이상치로 판정
✓ 이상치는 분석 결과의 질을 떨어뜨리거나 왜곡시킬 수 있으므로 제거하거나 다른 값으로 대체하는 경우가 많지만,
상황에 따라서는 제거하지 않고 분석해야 하는 경우도 있을 수 있음
이상치 탐지 방법
- Z-Score
자료가 평균으로부터 표준편차의 몇 배만큼 떨어져 있는지를 나타내는 지표
① 양의 Z-Score는 자료 값이 평균보다 높음을 의미
② 음의 Z-Score는 자료 값이 평균보다 낮음을 의미
③ 0에 가까운 Z-Score는 자료 값이 평균과 비슷함을 의미
④ Z-Score가 3 이상이거나 -3 이하면 일반적으로 이상치로 판단함
* 이 기준은 관습적인 지침이므로 절대적인 기준이 아님
* 상황에 따라 ±2가기준이 되거나 ±4가 기준이 될 수 있음 - IQR(Inter Quartile Range)
- 1사분위수와 3사분위수 간의 거리 = 3사분위수 -1사분위수
- IQR을 활용한 이상치 범위 = 이상치 < 1Q –1.5 X IQR , 3Q + 1.5 X IQR < 이상치
✓ Z-Score와 IQR을 활용한 이상치 범위를 비교하면 전반적으로 비슷하게 형성된다.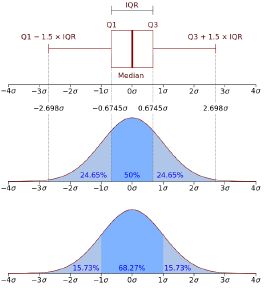
Z-Score와 IQR을 활용한 이상치 범위 비교
Box Plot (상자 도표)
5개의 수치적 자료를 활용해 데이터의 분포와 범위를 표현한 그래프

▶ 데이터 분석 모델링
모델링/모형 = 수식을 세우는 것
회귀분석 두 개 이상의 연속형 변수(수치)인 종속 변수와 독립 변수 간의 관계를 파악하는 분석
알고싶은 값을 예측하고자 할 때 상관분석은 데이터가 어떤 방향으로 움직이는지 파악할 뿐 그 정도는 알 수 없다. 회귀분석의 경우 두 변수 간의 관계를 파악해 알고자 하는 값을 예측할 수 있다.
예를 들어 매출이 오른 이유를 조사한다고 할 때 광고와 같이 매출 상승을 설명할 수 있는 변수들을 독립변수, 이에 따른 결과인 매출을 종속변수라고 할 수 있다.

광고비(독립변수)의 매출(종속변수)에 대한 영향력을 판단하기 위한 방법 중 하나로, 변수 간의 관계를 보여주는 회귀분석을 사용하여 적합도를 추정해 낸다. 이 때, 회귀분석의 결과가 변수 간의 인과관계를 직접적으로 설명해주는 것은 아니라는 것을 주의해야 한다.
'학습기록' 카테고리의 다른 글
| SQL(My SQL) 1주차 (0) | 2024.04.04 |
|---|---|
| 4주차 학습 메모_파이썬 (0) | 2024.03.11 |
| 3주차 학습 메모_파이썬 (0) | 2024.03.08 |
| 1주차 강의 메모 (0) | 2024.02.20 |
| 패스트캠퍼스 데이터 분석 부트캠프 13기 OT (0) | 2024.02.19 |

